A deep understanding of how we use gpt-3 and other NLP processes to build flexible chatbot architectures that can handle negotiation, multiple conversation turns, and multiple sales tactics to increase conversions.
The business abilities that chatbots provide to companies trying to scale different facets of their operations is no longer a secret. The automation power that chatbots provide for industries such as sales, marketing, customer service, company onboarding and more have allowed companies to scale these much faster and efficiently. With automation statistics like these it’s hard to ignore what chatbots are doing to companies.
Chatbots are the fastest growing branch communication channel - Chatbot use for branch communication is up 92% since 2019. (Source: Drift)
67% of global consumers had an interaction with a chatbot over the last 12 months. (Source: Invesp)
41.3% of consumers use conversational marketing tools for purchases - Up 17.1% since 2019. (Source: Drift)
But alongside the serious benefits from an automation and workflow scaling side, more modern chatbots are being used in a new way that is showing even more serious results for business. We’re building chatbots with a new approach to the architecture that allows us to use them for sales negotiations, lost customer conversion, taking customers from competitors, ecommerce support, and much more. These architectures learn how to use sales and marketing tactics that actually increase conversions and sales, and automatically learn how to improve based on successful results. Given the right data these chatbots can reach a level of personalization in their messaging that has been proven to be successful, with 80% of consumers saying they’re more likely to purchase from a personalized experience.
Sales driven chatbots can become 30% of a store's sales. (Source)
Abandoned cart chatbots can boost revenue by 25%. (Source: Chatbots Mag)
How can we build chatbots to do things like this?
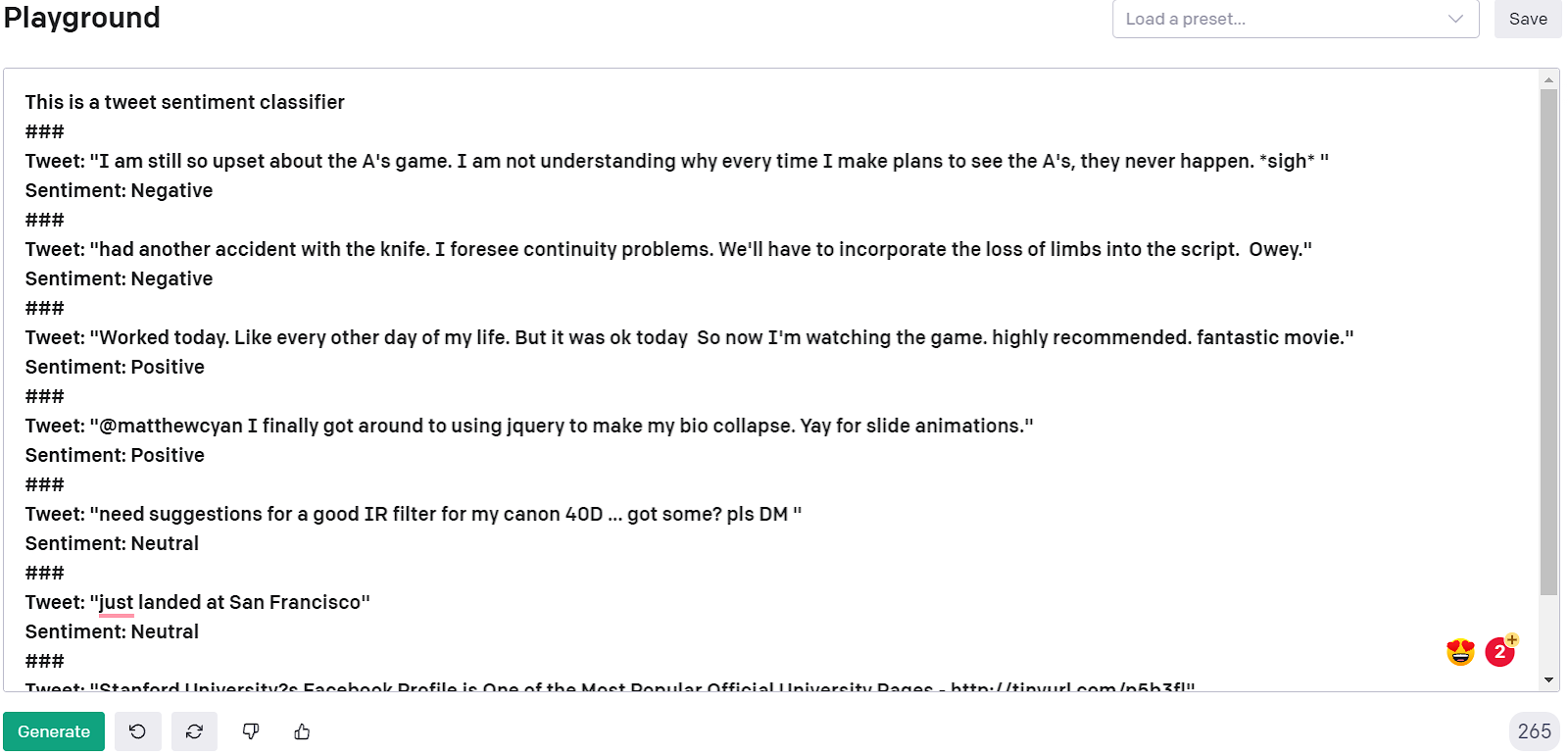
What Is GPT-3?
GPT-3 is a large language model that is built to be used for a wide variety of natural language processing tasks. The model is incredibly huge at 175 billion parameters and trained on 570 gigabytes of text. At a high level the model works to predict that next word in a sentence, similar to what you see in text messaging or google docs. This idea of generating the next word is based on tokens and is used for more than just the next word, but entire sentences and articles. The model can either be fine-tuned in a similar way to how we train neural networks, or can be used in a shot learning method. Few-shot learning is the process of showing GPT-3 a few examples of a task we want the model to accomplish and the correct result, such as sentiment analysis, and then running the model on a new example. This learning method is incredibly useful and efficient as it allows us to start getting results for our task without long training and optimization. With just a few examples of tweets and their sentiment, we were able to achieve 73% accuracy with few-shot learning!
The idea is gpt-3 will learn the best way to reach what you consider a correct result for any task where it can generate text. It will use the prior information to conceive a result that fits similar information that is available via prompt examples or its baseline language model. We essentially use the prompt and other tools to direct GPT-3 towards an understanding of our specific task and results that make sense. Remember, GPT-3 will just use the information given to reach a result, no matter if it’s correct or not. Like most machine learning tasks the data drives the results so if the data you give is poor (wrong labels, not generalized, no variance, different tasks) then the results you will get are poor.
We’ll discuss other parameters such as temperature, engine, Top P and api endpoints such as completion, search, answers for this model throughout the different builds and gpt-3 chatbot examples.
Using GPT-3 To Build Chatbots With Never Seen Learning & Flexibility | Beginning
With the given principles that define GPT-3 above we can generate responses to user input relatively easily. In our prompt examples we’ll define who is the bot and who is the human just as you see in chatbots. GPT-3 even has a few playground examples that let you play with very basic chatbots layouts for various tasks. The examples are laid out for different use cases and niches to show the variation you can achieve with just a bit of few-shot learning.
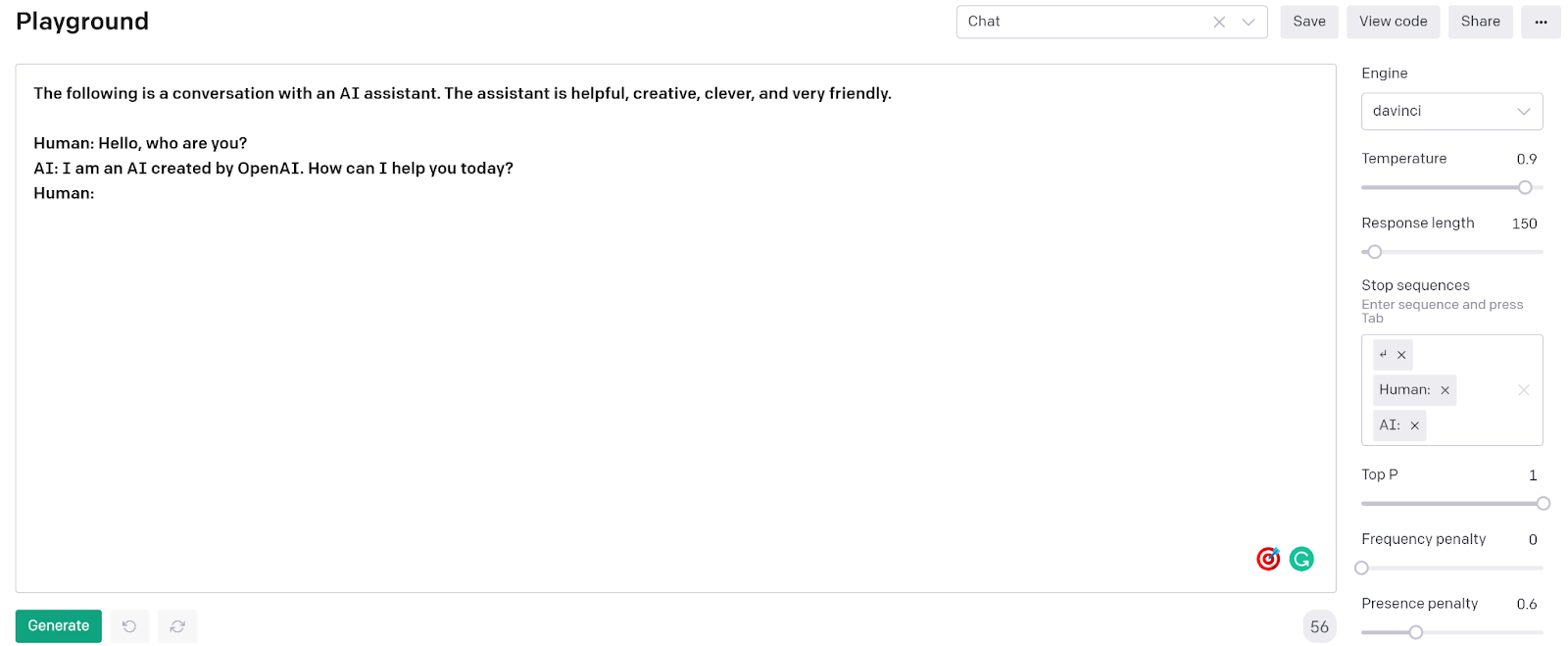
The “Chat” example in the GPT-3 Playground
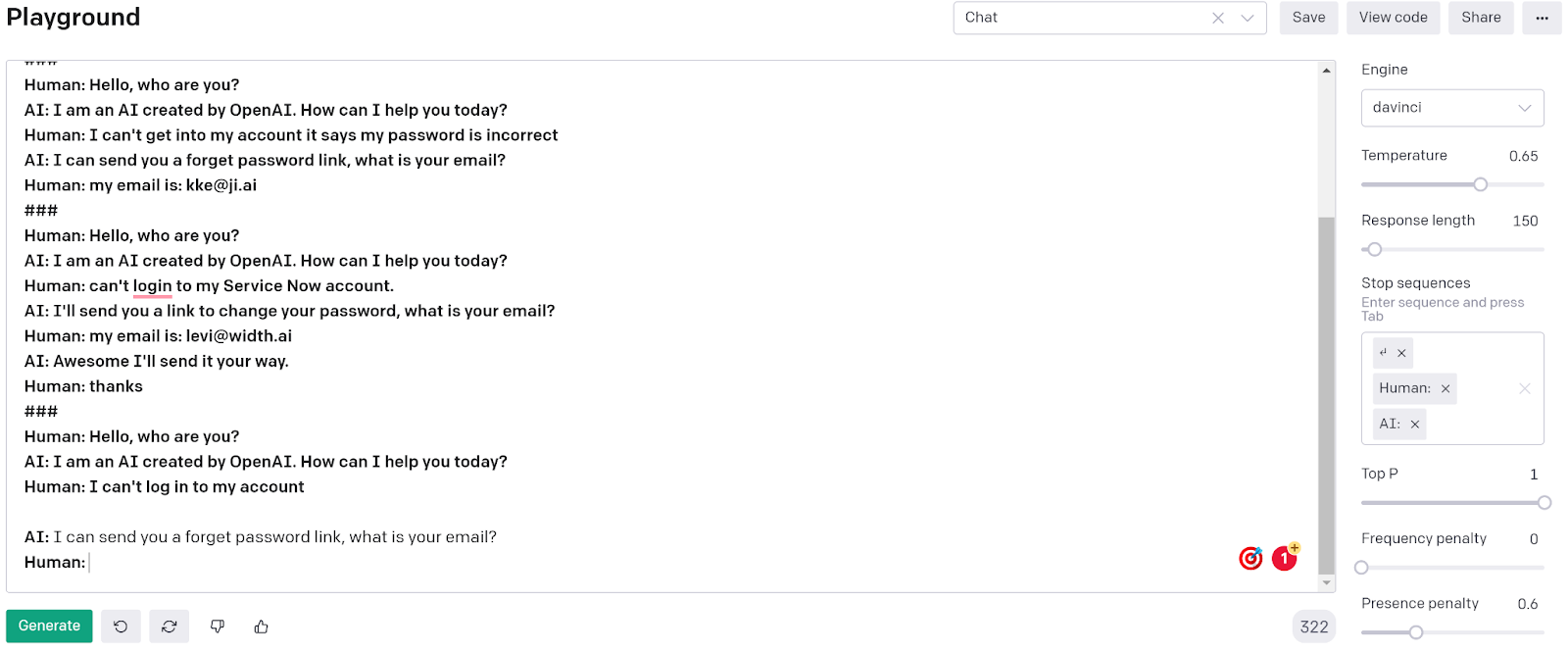
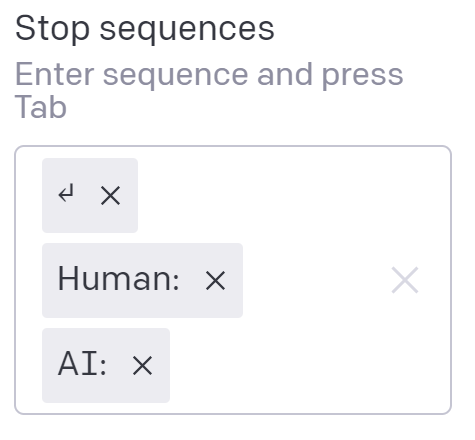
Here’s the default layout for the chatbot example in the GPT-3 playground. It has a prompt header and an initial human message and a default bot reply. It uses the davinci engine which is considered to be the highest accuracy generalized engine. The playground example also defaults to use the above stop sequences when running the model. This keeps the chatbot from typing more than just a reply to the human’s message.
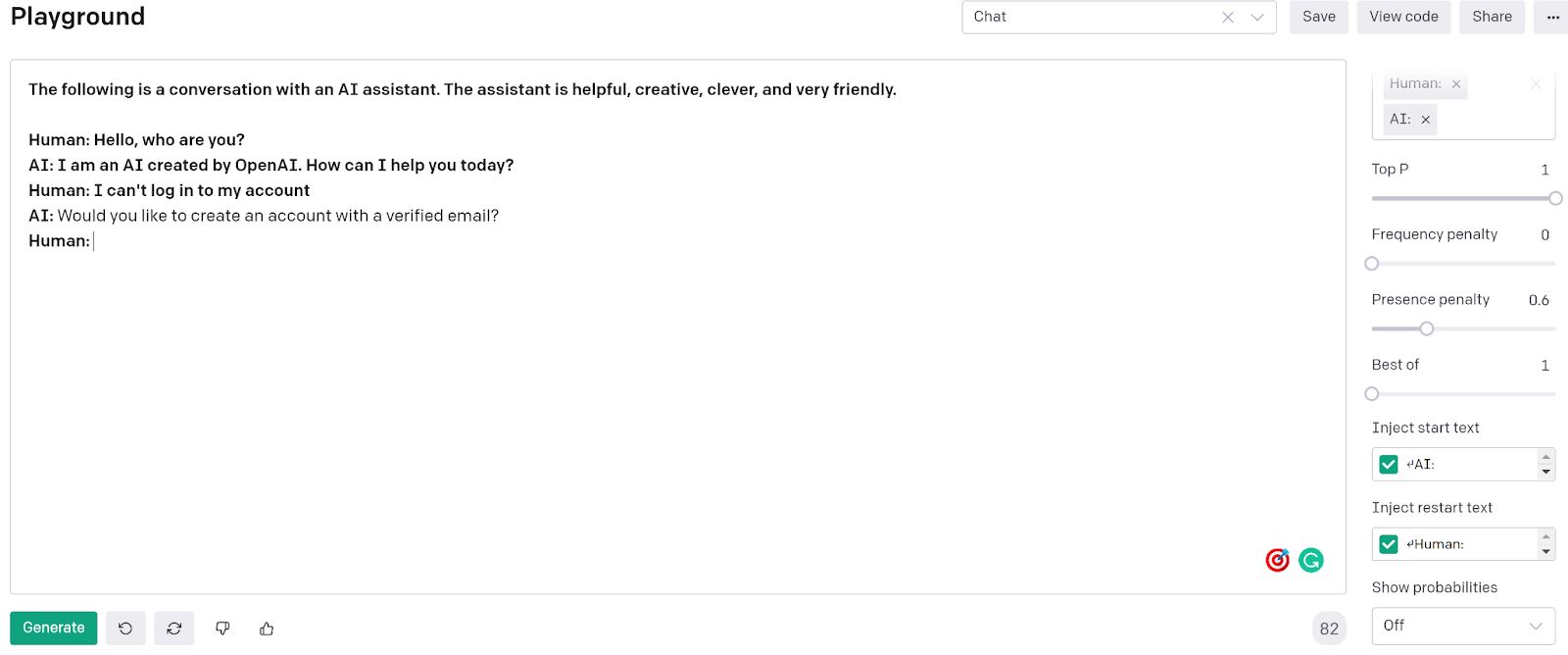
Let’s put in a message for the bot to respond to “I can’t log in to my account”. The gpt-3 model takes everything above it in the prompt and runs through to produce a response that says “Would you like to create an account with a verified email?” before stopping and injecting restart text. This response is close to what we probably want, but we’d probably want something like “Alright I can reset your password” or “Here’s a link to reset your password, what’s your email?”. Let’s talk for a second about why we got this result, trust me it will help later.
The current chatbot model is a zero shot learning model. Meaning outside of the chat related to this conversation (which could be considered learning, but is much more short term and doesn’t provide information about what to say in this exact instance) there aren’t any prompt examples to help guide the model towards what we consider correct.
The model used it’s large language model training to produce this answer. Given the millions of words and sentences it’s seen before this was most correct.
The temperature value. Temperature tells the model how much to “adventure” and control randomness. The idea is as your temperature gets closer to 0 the model becomes deterministic and repetitive to just follow orders. It stops reaching as deep into it’s possible responses and just focuses on any prompt examples or fine-tuning. The temperature is at .9 which is extremely high.
Presence penalty. Presence penalty affects how often words and language vary in terms of keywords. The parameter will penalize the model when repeating tokens and control the ability to talk about new topics.
There isn’t really any information in the prompt header or past conversation to suggest that we are discussing passwords or login information. Although the header isn’t as valuable as the rest of the prompt information, in testing and prompt optimization we’ve seen it can slightly affect language used and models understanding of the task.
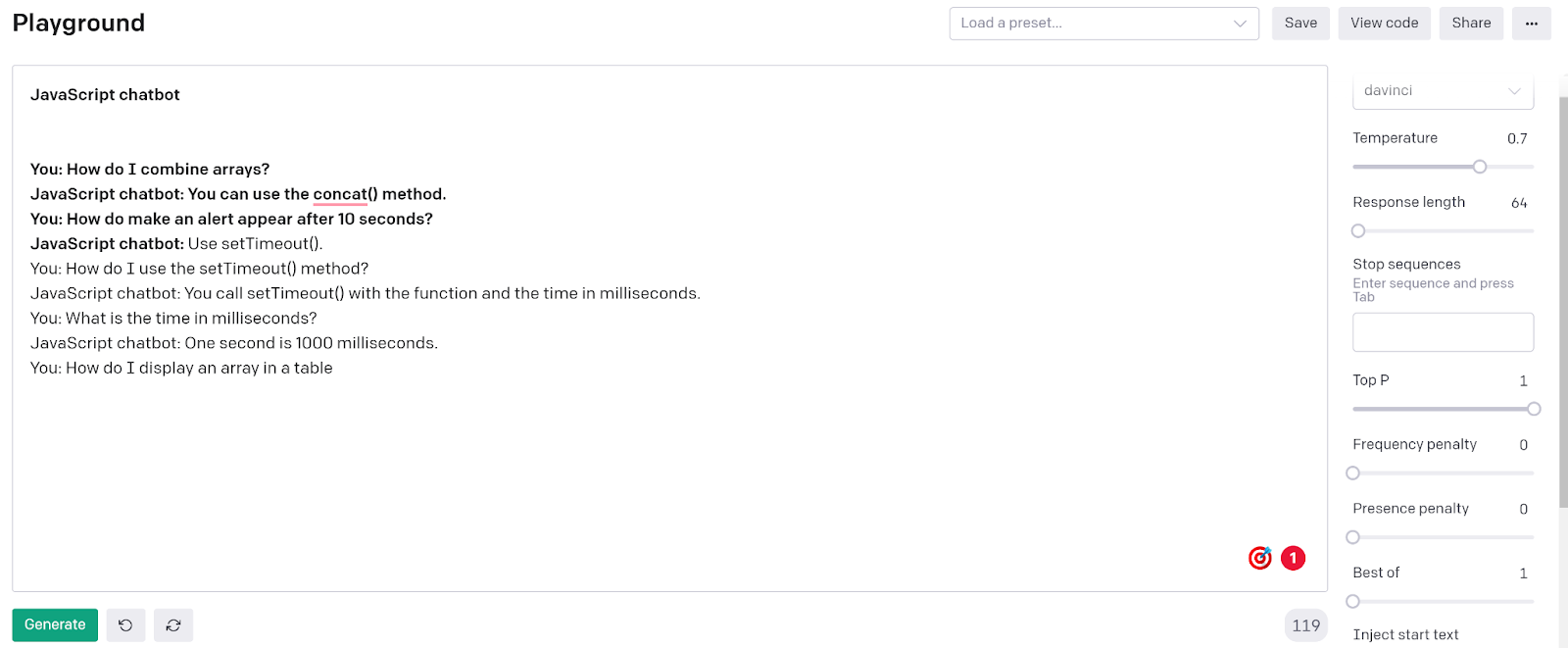
Even though the model struggled to produce a zero-shot output that we liked, it's not the end of the world for GPT-3. Here’s a look at the output from one of the other zero-shot chatbots in the playground examples. This is a javascript chatbot that answers questions related to javascript functionality with zero-shot.
This is about as much as you could ask for from a zero-shot chatbot in terms of accuracy and response quality. From just the prompt header and a single message and response the chatbot responds with a perfect javascript function for the question.
Improving Our Basic GPT-3 Chatbot
Let’s go back to our original chatbot that we can use as a customer support bot. We’re going to add some prompt examples to see if we can get a better response for our original question.
We could use a GPT-3 keyword extraction model like this one we built to get emails automatically (Read)
We’ve added a few examples of correct conversations and prompt examples. You’ll notice to verify the models ability to understand semantic similarities I included examples that are close but not exact language. Just a few examples of these conversations gets us to be able to cover this specific case (To prove I didn’t just type this I’ve left the models response in it’s default unbolded font). Of course however we want to be able to cover more than just one example of one customer service issue. Do we have to create conversations and add them to our prompt for everything we want to be able to solve?
After adding two examples for each case we’re able to add coverage to these two customer support services. If we wanted to cover the conversation at more length we can simply add more examples that make sense for the conversation.
As you might have realized by now, GPT-3 prompts have a token limit. You’re allowed to have up to 2048 tokens or about 1500 words in your prompt when you run, and that includes any generated text. That means there's a limit to how many example conversations we can have. What that also means is based on the current prompt layout there’s only so many types of conversations that we can have some sort of coverage of. This means our few-shot learning goes down for a specific type of response every time we want to cover a new type of user input with a semantically similar example. We’ll talk about how we cover this later.
Multi-Turn GPT-3 Chatbots With Prompt Optimization
We’ve seen how we can respond to multiple types of user messages and add prompt examples to help our chatbot understand how to answer semantically similar messages. What happens when our conversations get much longer or conversations change topics quickly?
As you can imagine this gets tricky as our model now has reached a point where there’s a few things to think about:
Our prompt examples were short one or two step conversations with the same start line. As we want to add the ability to cover longer conversations about the same topic should our examples grow in size or just have more? Should the examples be in the same format with the start line every time or should we split into a different example format? If we have long conversations as examples how do we account for the new fact that the entire prompt example probably won’t be semantically similar to our user input.
How do we account for the now much greater data variance in conversations that take multiple turns? Normal chatbot architectures struggle with the ability to understand turns in the conversation and produce output that aligns with the current user input. Should we just add a bunch of examples with turns and hope for the best?
Prompt Optimization For Both Use Cases
Prompt optimization allows us to dynamically put the exact prompt examples infront of our chatbot conversation that lead to a high accuracy understanding of how to flow in the conversation. This helps solve the requirement of covering larger data variance in our prompt examples for any given conversation as we no longer have to worry about token limits. No matter the user input our prompt optimization algorithm chooses the best examples we have to match the conversation. This gives us insane flexibility to cover turns and long form conversations now that we just have to focus on the last user message.
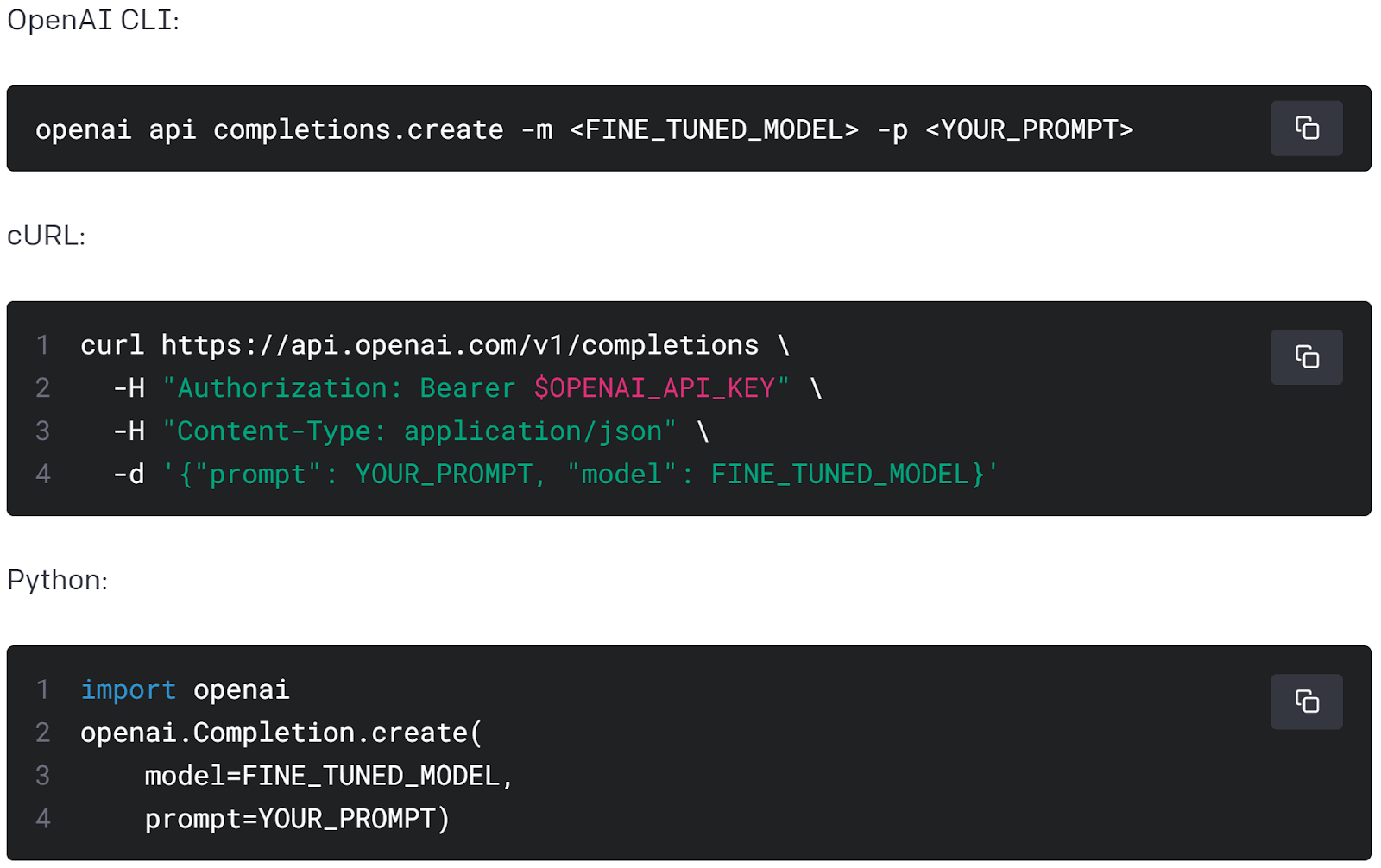
We’re going to use a prompt optimization framework we built internally called Simal.ai to handle all the processes we need for multi-turn and long conversations in our chatbot. This algorithm changes the game for us as we move our simple chatbot shown before into this scaled production level GPT-3 chatbot with the ability to produce accurate responses for a wider range of user messages. Once we’ve moved our prompt examples into a database (we’ll get to this in a second) we just pass the conversation through our prompt optimization algorithm and it produces a prompt that looks similar to the one we saw above. The key difference is that we’re going to use the GPT-3 API instead of the playground to allow us to turn our simple chatbot example into runable code.
Make sure you have your OpenAI API key set up and all the dependencies are installed! Use the Simal.ai confidence metric with the following command: simal.produce_confidence()
Simal.ai will use its prompt optimization to understand which examples from full_examples are the best and most relevant based on the current stage of the conversation. This let’s us rework our prompt at every turn in the conversation dynamically! On top of that, long conversations no longer run the risk of becoming unrelated to any examples we could have in a limited prompt. We just have to cover these user messages in any example we store. To clear up any confusion let’s talk a bit about the data format we want to use for these prompt examples.
One quick note to make before moving on. As you have probably noticed the responses our GPT-3 chatbot gives are almost exactly the same as the semantically similar examples. The language the bot uses doesn’t change much and just simply follows what worked before. This is because the language model has a bias towards prompt information over it’s large training. To allow the model to adventure more in the language it uses past prompt examples we can adjust the temperature parameter.
Data Formatting For Multi-Turn & Long Conversations
With a more complex chatbot and a new algorithm to create our prompts dynamically we need to store conversation (prompt) examples in a database to use. From our basic example we have a bunch of conversations that we used in our prompt that are called prompt examples. The key is that we consider these to be correct and that gpt-3 should model it’s understanding of how to solve similar tasks to them based on the language used. Never add prompt examples to any prompt that are incorrect.
This is a single prompt example. It shows a correct conversation between the chatbot and a user, with splitter characters ‘###’ and variables ‘AI’ and ‘Human’. At a simple level we want to add a bunch of these to our database to use dynamically when a conversation is started.
Here’s an example conversation we can add that is longer and goes through a few turns.
We want to add conversations of varying length mostly to provide the GPT-3 chatbot with clear cut examples of how long our conversations can go. Although these longer conversation examples don’t always provide high semantic similarity to a given multi-turn conversation they provide an increase in data variance. Our prompt optimization algorithm will handle choosing between these longer conversations for prompt examples or shorter more semantically similar conversations automatically. Usually we’ll want to use a mix of the two and use specific contextual checks to the examples and user conversation to optimize.
Both prompt optimization and data formatting can vary based on how we pass our conversation into GPT-3 at runtime. Here’s the two main options.
Pass the entire conversation up to this point into the model. It makes it more difficult to see any specific prompt examples as clear cut examples of the conversation but does allow your GPT-3 chatbot to use the past conversation as a part of the new response. This idea of short term memory can become important when going in-depth on a single topic in the conversation.
Pass just the most recent part of the conversation into the model, ignoring previous messages from this back and forth. This allows you to get much higher accuracy prompt examples for this given response but does limit the language you can use as the model cannot use anything discussed before.
Whichever path works best for a given use case will affect how we build our examples database and how the prompt optimization algorithm works. This will also have to be taken into account when we look at multivariable chatbots.
Multivariable GPT-3 Chatbots For Language Flexibility & Faster Learning
We’ve already seen multiple examples of how GPT-3 gives us incredible flexibility in how we can construct our chatbot architecture. Tools like prompt optimization give us the ability to scale our chatbots conversational abilities past the bounds of token limits or normal hard coded responses. Now we’re going to look at how we can use variables in our conversations to add more flexibility and dynamic nature to our chatbot's ability to produce correct responses. Variables can be used to negotiate prices, assist in customer service, provide user information and much more. While these variables allow us to do all of these things above, they do add a few complexities to what we’ve laid out.
Having prompt examples that are relevant to our input conversation is much more challenging and requires a much more complex prompt optimization algorithm.
Our chatbot cannot be as simple as a prompt header and examples. Our language model needs to learn the relationship between variables and generated output as well.
The model will pick up bias much easier towards specific “paths” to solve a given conversation. Biases between variables and a generated result can happen more often as the model cannot just focus on conversation language.
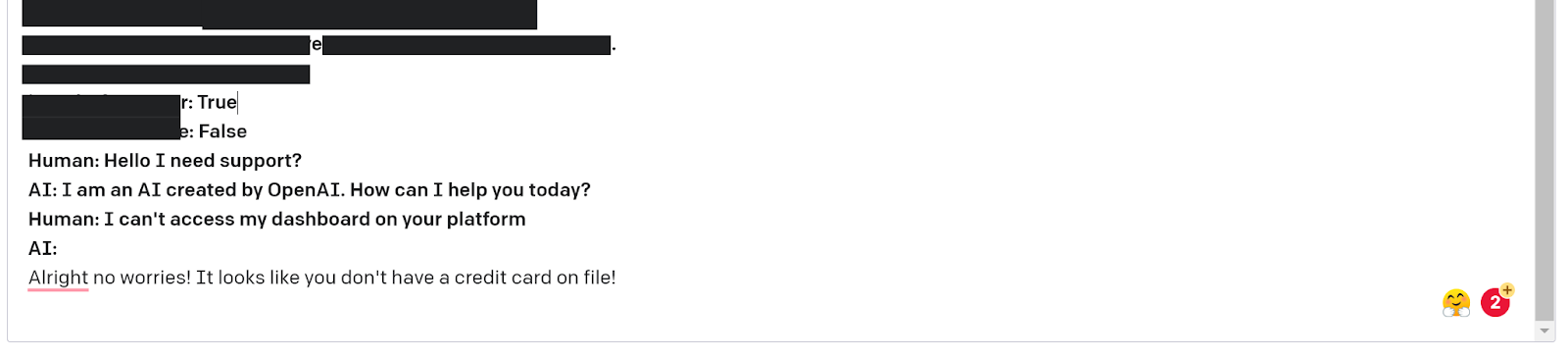
We’re going to create a multivariable chatbot to help users figure out why they cannot use our SaaS platform. We’ll provide a number of variables to the chatbot around user information such as “are they already a user”, “is there a credit card on file”, “days since last login”, “account level”. These variables will be what the GPT-3 model uses to correctly assist the user with their issue.
We set these variables and receive a generated output that decides we need to look at the credit card the user has stored on the platform. Of course in a real system we have outside logic that creates these variables in our GPT-3 prompt. We would want pipelines to check if they’re already a user, have a credit card on file etc.
Quick tip: Save your different versions to a config file. That way you can keep track of the new things you try.
Here we change just one variable and get an entirely new response for the same human message! Our model clearly understands how to use variables, and the level of importance they have for the conversation. Our responses can also help guide the user to the next step to increase conversions. This is incredibly important when we’re trying to build chatbots that not only allow us to automate these workflows but still hold high conversion rates and even outperform high volume human based customer support.
Customer support with in-context variables
Here we get the user who doesn’t have an account and can’t seem to access the platform. Understanding that they don’t have an account we can recognize the issue via variables and give them a solution in the same response. This makes it easy for the person at the next step to keep moving along with just a yes or no. This level of complexity in responses is more difficult to achieve but really takes the workload off potential customers. We use an in-context variable as well to provide a signup link before showing the response on a UI.
If you’re using a default set of options for a chatbot user to choose from on their first message simply pipe them into the chatbot as the first lines. Although setting defaults for the user to pick from limits them a bit, we can make their experience easier and our chatbot much stronger. Our responses can be much more in-depth which should be the focus with conversion optimization.
Quick point to note. Generating in-context variables like [%Pricing%] is the same as any other word. The model learns to generate that token as best case just as it does any other word or part of word. This is a great way to add prompt examples to a database that contain proper nouns without limiting the language to specific peoples names or businesses. We often want the model to learn the language around these proper nouns, but be able to substitute our user's name or business. You can also use variables pertaining to the person or business to adjust the language for gender or race as we’ve seen in this case study.
Prompt Optimization & Variable Handling
We’re going to use built in features in Simal.ai to handle both prompt optimization and variable handling. We’ve already seen how we want to do prompt optimization before for multi-turn and long conversations. We’ll also look at how we can deploy modules to handle grabbing variables for our live conversations and how we can fill in-context examples on the way out.
Prompt Optimization For Multivariable Chatbots
The prompt optimization we use for this chatbot is essentially the same as we’ve seen above. We have an algorithm that picks prompt examples from a database dynamically based on the current conversation. These prompt examples should include similar variables to what we’re currently using for talking to users. Updating past prompt examples to match our current format is important as well. We want to be able to adjust our examples to closer fit any changes we make to variables or in-context variables.
Variable Handling For Artificial Intelligence Bots
We want to be able to connect and integrate our data variable sources to the functionality that creates our prompts and runs GPT-3. This can be things like the Zillow API to get house data, a customer's account data to have an informed conversation, ecommerce product data to answer customer questions, or any other data sources. We’ll build these modules to integrate different APIs into our app to pass dynamic variables. Something to keep in mind is that it should be assumed this is the most private conversation between human and bot. Part of the data side here is replacing names with variables.
An interesting concept to think about is what if we want to pass other GPT-3 results to our own chatbots? Let’s say we have a sentiment analysis model that we run customer questions through to understand how users respond. We can use the result as a variable in our chatbot to steer the conversation. Say the user is extremely angry while having issues with customer support. We can adjust how we respond when talking to the user and use different language. We might be less inclined to provide helpful resources and instead quickly solve the issue or move them to human support.
In-context variables are much easier to work with. Mostly we write ai based rules and build a separate database to store the information that we want to replace these variables with. As the pipeline looks to pass the generated output to the UI we have a module check and replace any of these variables. This module can also be used to store the conversation in memory for use at the next human message or store in a database for our own purposes at a later date.
The spaCy library provides different NLP rules and pattern recognition tools to use for this once integrated into our main GPT-3 bot pipeline.
GPT-3 Chatbots Vs Artificial Intelligence Bots
There are alot of complex architectures out in the world of deep learning that can be used for complex tasks such as Multi-Turn and MultiVariable responses. They’re usually architectures with a focus on deep attention matching, sequential matching, or interactive matching with models like BERT used as an NLP backbone (take a read if you want - Read). While these models can produce good results at large scale for a number of chatbot domains there’s a few places where I think they’re behind GPT-3 bots.
Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
Deep Learning Requires Tradition Training & Optimization
These models require traditional training and optimization to reach higher accuracy. This process is slow and requires a ton of data if you’re starting from scratch. You can usually find some pre-trained model to get you started but if your domain is super unique it can become complex. GPT-3 will require much less data as we’re going with a prompt approach over a large architecture. You’re able to get off the ground much quicker and make adjustments much easier which you’ll find to be beneficial as you move towards production.
Traditional Ai Chatbots Have Less Flexibility
The ability to make changes to your prompt framework and problem case with changes to variables, prompt examples, prompt headlines, and more is something you’ll have to do during product development and during the lifecycle as you optimize for business goals. GPT-3 makes these changes incredibly easy. One key idea to keep in mind is that we can use different variables at different times for the same GPT-3 bot. Depending on the conversation we can pipeline different variables in at different times. This insane level of flexibility is not usually achievable with traditional architectures.
We can also make entire changes to how we structure our chatbot framework relatively quickly and without retraining a large model for each tiny change. The benefit of this flexibility grows exponentially as you see how often you want to add new variables, adjust language used, adjust responses based on conversions, and more. Given the easy nature of prompt examples and prompts in general tiny tweaks to specific responses take a matter of seconds, whereas you might have to retrain the entire model with large architectures.
Data Generalization Actually Scales Well With GPT-3
One of the key advantages of large architectures is how well they scale in the long run to cover more data variance. These systems are trained on millions of examples and allow you cover that variance essentially overnight with training. As we saw in our first example OpenAI’s API has a prompt that has a limit of 2048 tokens as the only information you can make available. But with the newly released fine-tuning and the prompt optimization we discussed throughout we can reach the level of data variance you see with large architectures.
A look at using a fine-tuned model. Reminder that you can store your OpenAI API key in an env file and grab it via OS.
Fine-tuning allows you to use a ton more examples in a layer between the large language model and the prompt itself. You can create a data file of examples and train the model like you would any other traditional architecture. All of the benefits and downsides we looked at to traditional training and optimization now come into play, but it’s a nice way to add a backbone level of task understanding to your model.
This is a very nice GIF by Jay Alammar to show fine-tuning.
Helpful Resources For Fine-Tuning
The following command creates a new fine in OpenAI database. Once again you should store your API key in an env file.
One thing that’s worth testing is searching the internet for conversation datasets talking even a bit about your domain. These datasets don’t have to be that close to be useful as a tuned backbone in our app. Create a tuned model then use our Simal.ai prompt optimization on top and we can see a difference.
Where To Go Next
Width.ai builds custom chatbots for tons of use cases and business domains at a scale that is unmatched in the market. We’ve built sales optimized chatbots, customer service chatbots, and even on page ecommerce chatbots to reduce clickaways. Reach out to us to find out how a chatbot can work in your industry.
Simal.ai is a product we’ve built to help companies productionize and scale GPT-3 based products. Take your basic GPT-3 model and turn it into a full scale product with optimization pipelines, state of the art confidence metrics, and ai powered alerting all built just for GPT-3.






















{kind=link}