The advent of large language models (LLMs) has revolutionized human-machine interactions, particularly in natural language understanding and generation applications. These AI- or LLM-backed virtual assistants hold the promise of serving as intelligent agents capable of autonomously reasoning, observing, and performing tasks articulated in natural language. However, it is still challenging for most agent frameworks to efficiently handle complex data structures (e.g., DataFrame), which are prevalent in data analytics tasks and domain-specific scenarios.
To address these challenges, we introduce TaskWeaver – a code-first agent framework which can convert natural language user requests into executable code, with additional support for rich data structures, dynamic plugin selection, and domain-adapted planning process. Now publicly available as an open-source framework, TaskWeaver leverages LLMs’ coding capability to implement complex logic and incorporates domain-specific knowledge through customizable examples and plugins. TaskWeaver empowers users to easily build their own virtual assistants that understand diverse domain questions, follow examples, and execute customizable algorithms on complex data structures efficiently.
Motivating example – Anomaly detection on time-series data
Scenario
Amy is a business analyst who wants to identify anomalies on a time series of sales data stored in a SQL database. She would like to get help from an AI assistant for the task with natural language interactions. Moreover, Amy would like to apply her own definition and interpretation of anomalies in the context of sales data, including a customized anomaly detection algorithm. Figure 1 shows the desired conversation between the user and the AI assistant – the AI assistant should be able to first pull the data from target database, then apply desired algorithms, and return the visualized results.
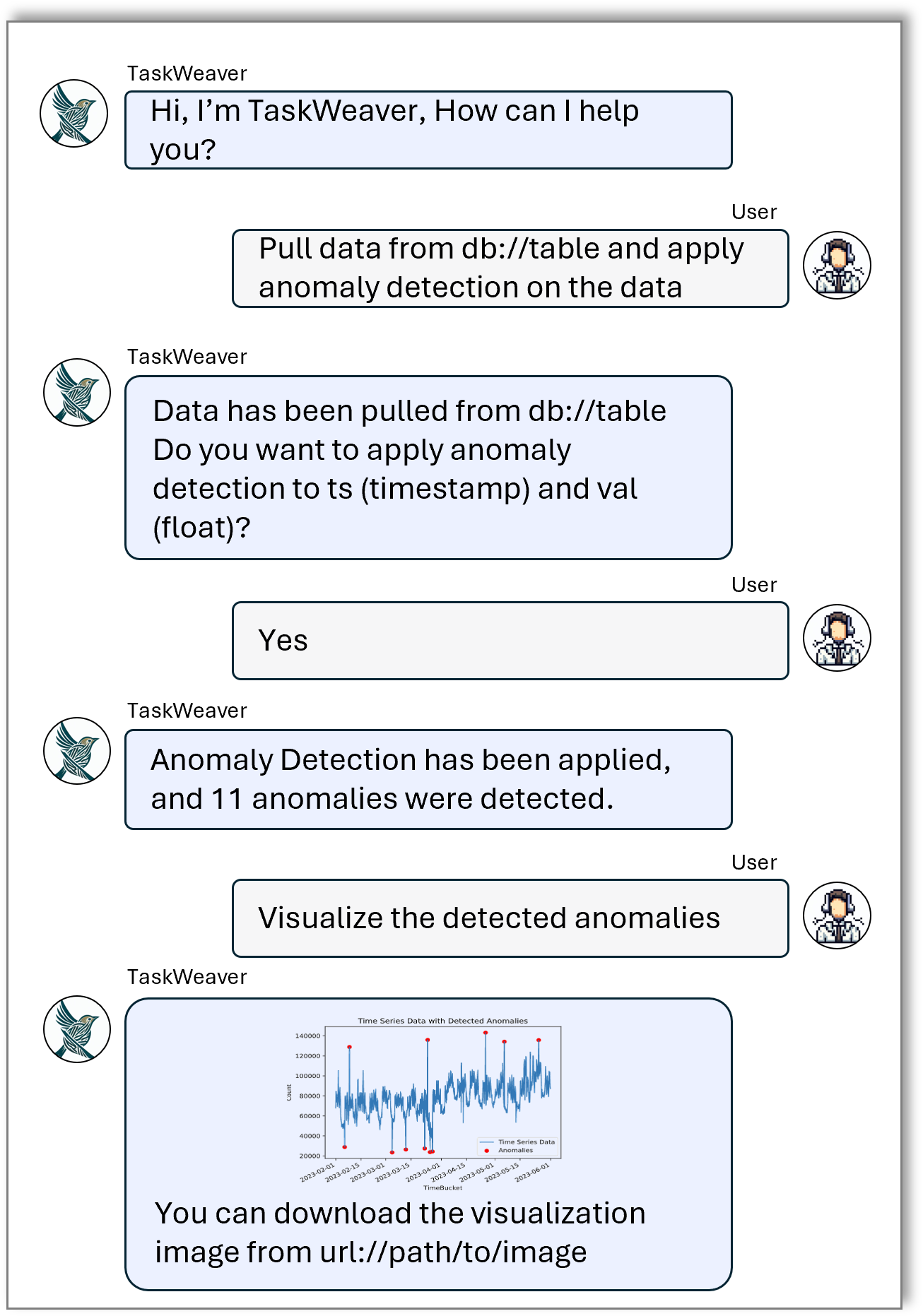
Requirements for an agent framework
To accomplish the task above, we identify several key requirements that current agent frameworks may lack:
- Plugin: The agent needs to first query and collect data from a database, and then detect anomalies using a specialized anomaly detection algorithm. Both require the capability to define and invoke custom plugins, e.g., the query_database plugin and the anomaly_detection plugin.
- Rich data structure: the agent should be capable of handling data in complex but common structures, such as array, matrix, tabular data (e.g., pandas DataFrame (opens in new tab)), to perform advanced data processing actions. Many existing works tend to transform the intermediate outputs as strings in the prompt or save them as local files before reading them again. However, this practice is error-prone and could easily exceed the prompt token limit. Additionally, data in rich structure should be able to transfer easily from one plugin to another.
- Stateful execution: The agent engages in iterative interactions with the user, processing user inputs and executing tasks accordingly. The execution states should be preserved throughout the entire conversation session across multiple chat rounds.
- Reasoning and acting (ReAct): The agent should have the capability to first observe and then act. The database might contain data of various schemas in the real world, leading to different arguments for anomaly detection. Therefore, the agent must first inspect the data schema, understand which columns are appropriate (and ask users to confirm), then feed the corresponding column names into the anomaly detection algorithm.
- Arbitrary code generation: The agent should be able to generate code to accommodate ad-hoc user demands, which are not covered by the pre-defined plugins. In the example provided, the agent generates code to visualize the detected anomalies without using any plugins.
- Incorporating domain knowledge: The agent should provide a systematic way to incorporate domain-specific knowledge. It would help LLMs deliver better planning and accurate tool calling, which in turn produces reliable results, particularly in domain-specific scenarios.
Microsoft Research Podcast

Collaborators: Holoportation™ communication technology with Spencer Fowers and Kwame Darko
Spencer Fowers and Kwame Darko break down how the technology behind Holoportation and the telecommunication device being built around it brings patients and doctors together when being in the same room isn’t an easy option and discuss the potential impact of the work.
TaskWeaver architecture
Figure 2 shows the three core components in the TaskWeaver architecture. The Planner serves as the system’s entry point and interacts with the user. Its responsibilities include: (1) planning – breaking down the user’s request into subtasks and managing the execution process with self-reflection; and (2) responding – transforming the execution result into a human-readable response for the user. The Code Interpreter consists of two components: the Code Generator generates code for a given subtask from the Planner, considering existing plugins and domain-specific task examples; the Code Executor is responsible for executing the generated code and maintaining the execution state throughout the entire session.
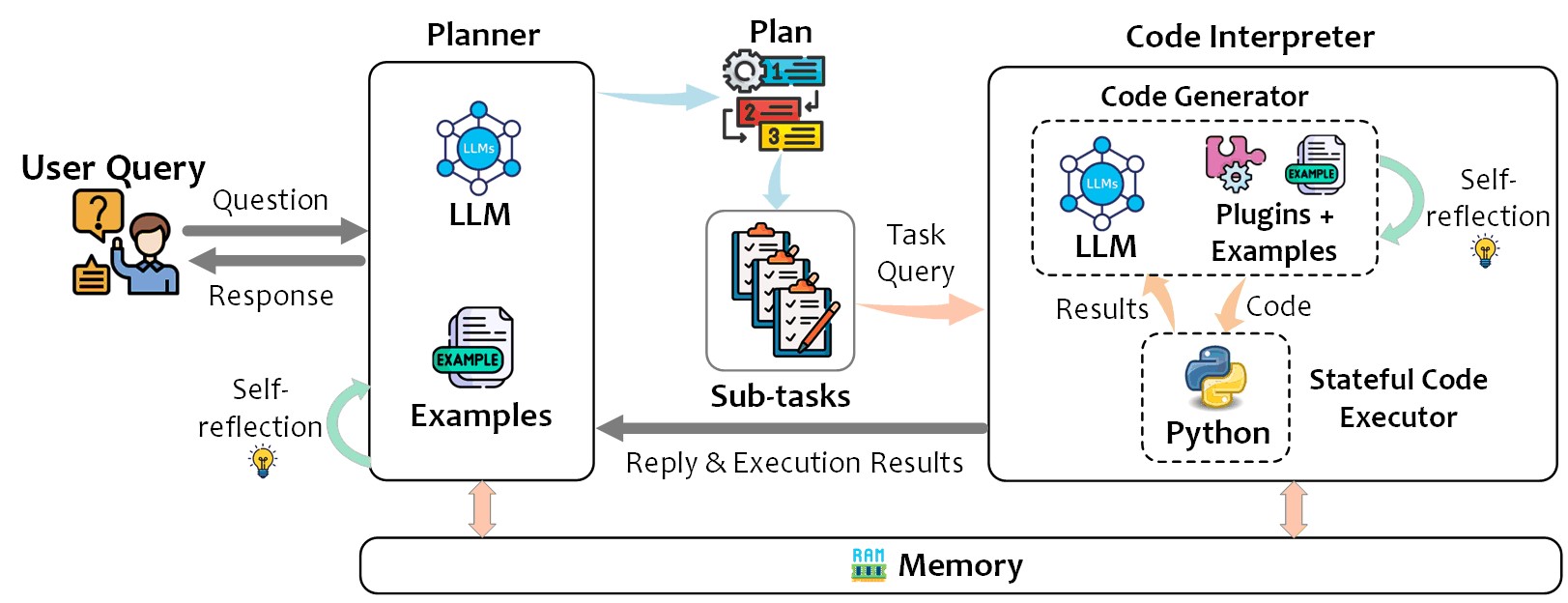
Running workflow for motivating example
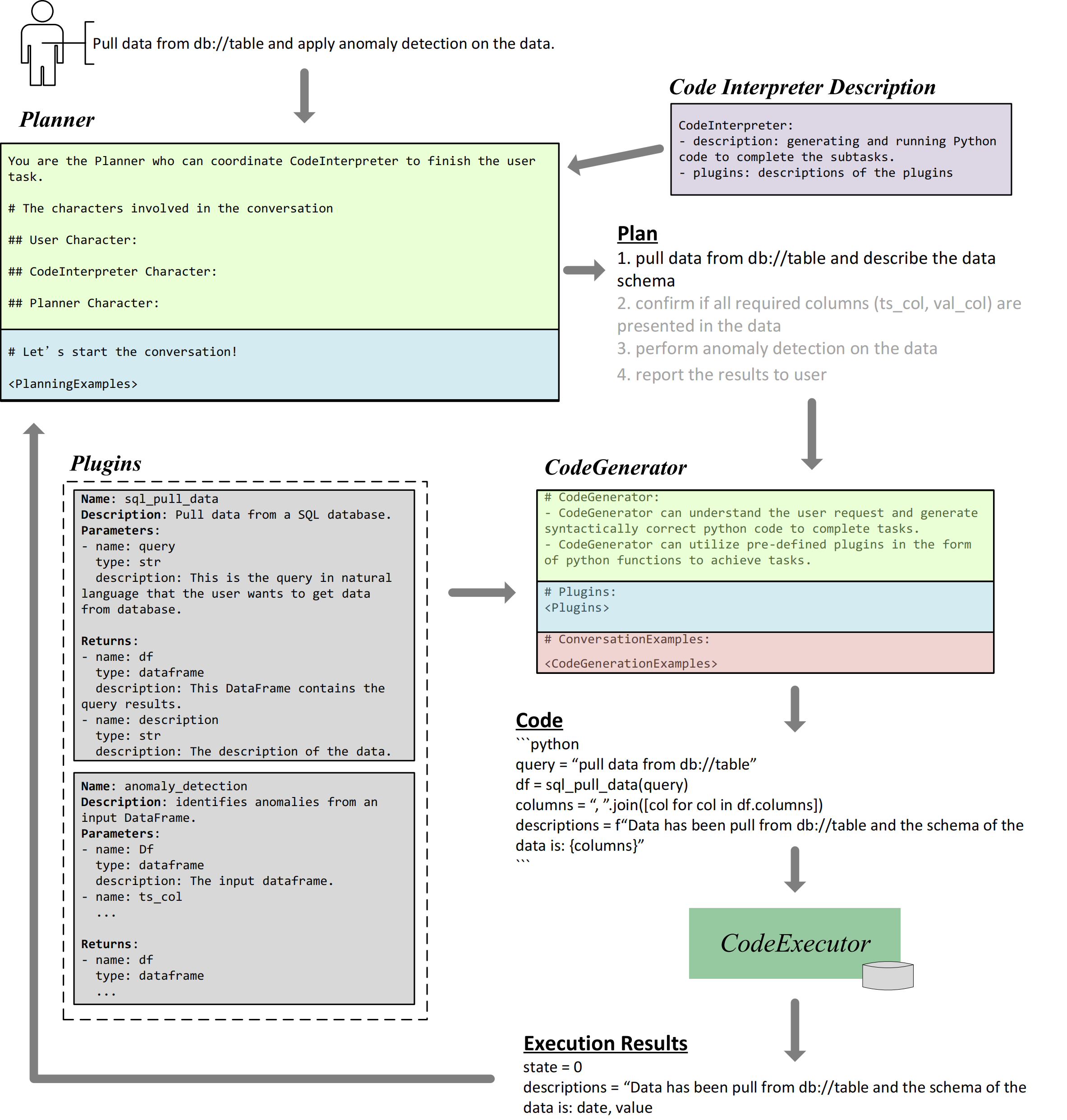
TaskWeaver has a two-layer planning process for dealing with user requests. In the first layer, the Planner generates a high-level plan outlining the steps required to fulfill the request. In each subsequent round, the code generator will devise a plan, in terms of chain-of-thought and generated code, to execute the specified step. Figure 3 presents the internal workflow of TaskWeaver when accomplishing the motivating example mentioned above. Note that the prompts shown in Figure 3 are simplified and do not represent the full complex instructions.
The initial step involves the Planner taking the user query, Code Interpreter description, and planning examples (if provided) to generate a plan. For the given example, the plan first pulls data from the database and describes the data schema. The Code Generator prompt delineates its profile and competencies, providing definitions of all relevant plugins (e.g., function name, description, arguments and return values.) The output from the Code Generator is a code snippet that executes the sql_pull_data plugin, retrieves the data into a DataFrame, and provides a description of the data schema.
Next, the code generated is sent to the Code Executor for execution, after which the result is sent back to the Planner to determine the next planning step. In the example, the execution result reveals two columns, namely date and value, in the DataFrame. For the next step, the Planner can either confirm with the user if these columns correspond to the two input parameters of the anomaly_detection plugin, or directly proceed to the next step.
Key design considerations of TaskWeaver
- Code-first analytics experience: TaskWeaver converts user requests into Python programs that run on dedicated processes, where the Python program can be plugin invocations, arbitrary code to handle ad-hoc user queries, or both. Unlike other frameworks that rely on text or file-based expressions, TaskWeaver can fully utilize native data structures such as pandas DataFrame and numpy ndarray that exist in the memory. This makes it easy to perform tasks such as pulling data from a database, running machine learning algorithms (e.g., anomaly detection, classification, or clustering), summarizing results, and visualizing analysis outcomes.
- Domain adaptation: Incorporating domain-specific knowledge into the model via prompts can help boost LLMs’ performance when the user query is complex. TaskWeaver provides two options to make customizations with the user’s domain knowledge:
- Customization with plugins: Users can define custom plugins (including Python implementation and schema) to incorporate domain knowledge, such as pulling data from a specific database, and running a dedicated algorithm.
- Customization with examples: TaskWeaver also provides an easy-to-implement interface (in YAML format) for users to configure examples to teach the LLMs how to respond to certain requests. The examples can be of two categories: one is used for planning and the other is for code generation.
- Stateful code execution: When users make ad-hoc requests for data analytics, it often involves multiple iterations. As a result, TaskWeaver maintains the state of code execution throughout the entire session. This is like programming in Python using the Jupyter Notebook, where users type code snippets in a sequence of cells and the program’s internal state progresses sequentially. The difference in TaskWeaver is that users use natural language instead of programming language. TaskWeaver converts each user request into one or more code snippets in each round, depending on the specific plan.
- Others: TaskWeaver also supports other features such as intelligent plan decomposition and self-reflection to respond to a user’s request in a more reliable and organized manner. Moreover, features like restricted code generation can help limit the capabilities of the generated code to reduce security risks.
Getting started
TaskWeaver (opens in new tab) is now publicly available on GitHub. You may run the following commands to quickly get started.
git clone https://github.com/microsoft/TaskWeaver.git cd TaskWeaver pip install -r requirements.txt # install the requirements
Once the installation is finished, users can configure key parameters, such as the LLM endpoint, key and model, and start the TaskWeaver service easily by following the running examples (opens in new tab).
Other resources
- Video demos: The Demo Examples (opens in new tab) show two demo videos, the first one covers the motivating example presented above on anomaly detection; the second shows the case to forecast the price of Invesco QQQ Trust, an exchange-traded fund, over the next week.
- For more information, please refer to the TaskWeaver documentation. (opens in new tab)
- Technical report with mode details on design considerations: technical report.