Introduction to Automated Machine Learning
AutoML enables developers with limited ML expertise (and coding experience) to train high-quality models specific to their business needs. For this article, we will focus on AutoML systems which cater to everyday business and technology applications.

What Are AutoML Systems?
Machine learning (ML) – as a subfield of the broader domain of Artificial Intelligence (AI) – is taking over all kinds of industries and business domains. This includes retail, healthcare, automotive, finance, entertainment, and more. With this wider adoption across all kinds of operations and by a workforce with a diverse set of skills, learning how to work with machine learning is becoming increasingly important.
Due to this expansion of ML usage by the ever-increasing cross-section of employees in an organization, it has become critical to develop systems that can be used by business professionals of all sorts of backgrounds. And that means these systems cannot exclusively be coding or programming oriented like the ones used by software engineers or data scientists.
This is where the AutoML systems enter the picture.
In short, AutoML enables developers with limited ML expertise (and coding experience) to train high-quality models specific to their business needs. There are other aspects of AutoML from an academic research point of view (i.e. searching for the best ML algorithms for given data types and proving theoretical properties about such systems); but for this article, we will focus on AutoML systems which cater to everyday business and technology applications.
Why Are AutoML Systems Gaining Popularity?
As mentioned above, professionals from all sorts of backgrounds and skillsets are coming into the field of data science and machine learning for their respective business or R&D activities. Not all of them have a rigorous background or formal training in statistical sciences or machine learning theory.
They just need to be able to source or ingest a dataset, follow a complete data exploration and model training workflow, and produce a trained model for an ML application downstream.
It would be more time-consuming on their part if they have to do all of these by themselves:
- search through all the possible ML algorithms,
- evaluate them on the training dataset,
- check the validation set performance in a rigorous manner,
- apply additional judgment (memory and CPU footprint) to select the best model for the end application.
AutoML systems, to a large extent, do all this heavy lifting for data scientists or analysts and automate or streamline the generation of highly optimized trained ML models for production-ready usage.
Consequently, these systems are gaining popularity among organizations employing heavy use of data science because they:
- save the organization manpower cost and headcount, as a relatively lean workforce can utilize such systems to train and optimize a large number of ML models
- reduce the chance of error by automating not only the model training and optimization but also the so-called boring aspects of data science (i.e. data ingestion, parsing, wrangling, and feature exploration to a large extent)
- reduce the time-to-market for a large percentage of ML-powered applications with a relatively high-performance standard
With respect to time-to-market, one can argue that the final result produced by an AutoML system may not be as performant or optimized as compared to the one architected by an expert ML engineer (using hand-crafted feature engineering or deep learning tuning).
However, this kind of hand-tuning is often a time-consuming process and, for most situations, getting to a production-ready status with a decent ML model in a relatively shorter amount of time is much more critical for an organization than wasting time on producing the absolute best performing model. AutoML systems help organizations achieve this critical business objective, hence its growing popularity and wider adoption.
Now organizations can simply get custom machine learning workstations for their workforce, install the tools like AutoML to quickly spin up a working machine learning based system, and move forward with the next steps in AI-ready production in order to go to market with their results quicker than ever.
Types of AutoML Systems & Some Prominent Examples
There are quite a few different types of AutoML systems as they cater to different categories of tasks in a data science or ML workflow.
Some types of AutoML systems include:
- AutoML for automated parameter tuning (a relatively basic type)
- AutoML for non-deep learning, for example, Auto-Sklearn. This type is mainly applied in data pre-processing, automated feature analysis, automated feature detection, automated feature selection, and automated model selection.
- AutoML for deep learning/ neural networks, including systems specifically designed for Neural architecture search (NAS) as well as utility packages like AutoKeras built atop the highly popular deep learning framework.
Auto-Sklearn
As the name suggests Auto-Sklearn is an automated machine learning software package built on scikit-learn. Auto-Sklearn frees a data scientist from the task of algorithm selection and hyper-parameter tuning. Essentially, it automatically searches for the right learning algorithm for a new machine learning dataset and optimizes its hyperparameters.
It extends the idea of configuring a general machine learning framework with efficient global optimization which was introduced with Auto-WEKA. To improve generalization, Auto-Sklearn builds an ensemble of all models tested during the global optimization process. In order to speed up the optimization process, Auto-Sklearn uses meta-learning to identify similar datasets and use the knowledge gathered in the past.
It includes feature engineering methods such as one-hot encoding, digital feature standardization, and principal component analysis (PCA). At its core, the library uses scikit-learn estimators to process classification and regression problems.
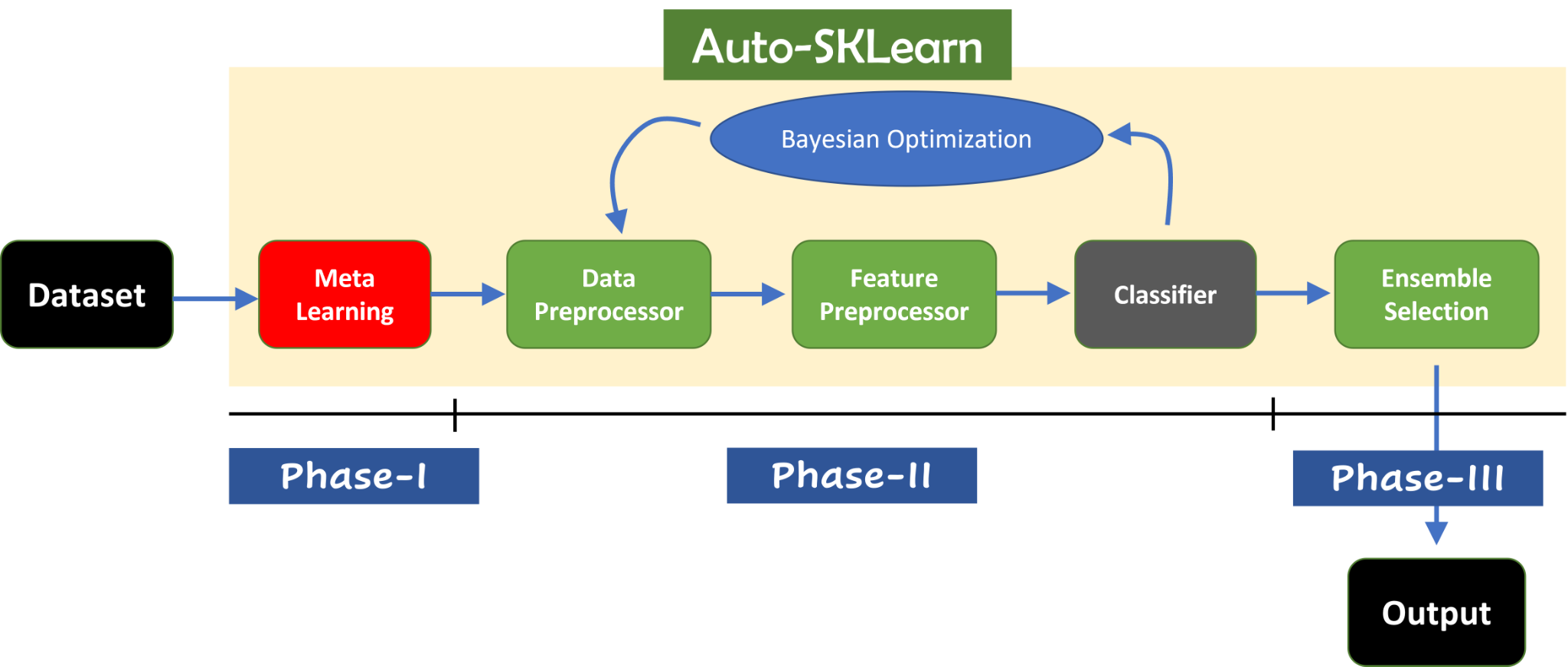
Auto-Sklearn workflow and diagram
Documentation: You can find the detailed documentation here.
Code example: Here we show a basic classification task code example with Auto-Sklearn. We build an ML model for classifying the numerical digits using a built-in dataset in the scikit-learn package.
import autosklearn.classification
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics
if __name__ == "__main__":
X, y = sklearn.datasets.load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = \
sklearn.model_selection.train_test_split(X, y, random_state=1)
automl = autosklearn.classification.AutoSklearnClassifier()
automl.fit(X_train, y_train)
y_hat = automl.predict(X_test)
print("Accuracy score", sklearn.metrics.accuracy_score(y_test, y_hat))
Note about OS: Auto-Sklearn relies heavily on the Python module resource. This module is part of Python’s Unix Specific Services and not available on a Windows machine. Therefore, as of today, it is not possible to run auto-sklearn on a Windows machine.
Possible solutions:
- Windows 10 bash shell (see 431 and 860 for suggestions)
- Virtual machine
- Docker image
MLBox

MLBox is a powerful Automated Machine Learning python library. According to the official documentation, it provides the following features:
- Fast reading and distributed data preprocessing/cleaning/formatting
- Highly robust feature selection and leak detection as well as accurate hyper-parameter optimization
- State-of-the art predictive models for classification and regression (Deep Learning, Stacking, LightGBM)
- Prediction with model interpretation
- MLBox has been tested on Kaggle and shows good performance
- Pipeline building
TPOT

TPOT is a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming. It is also built on top of scikit-learn.
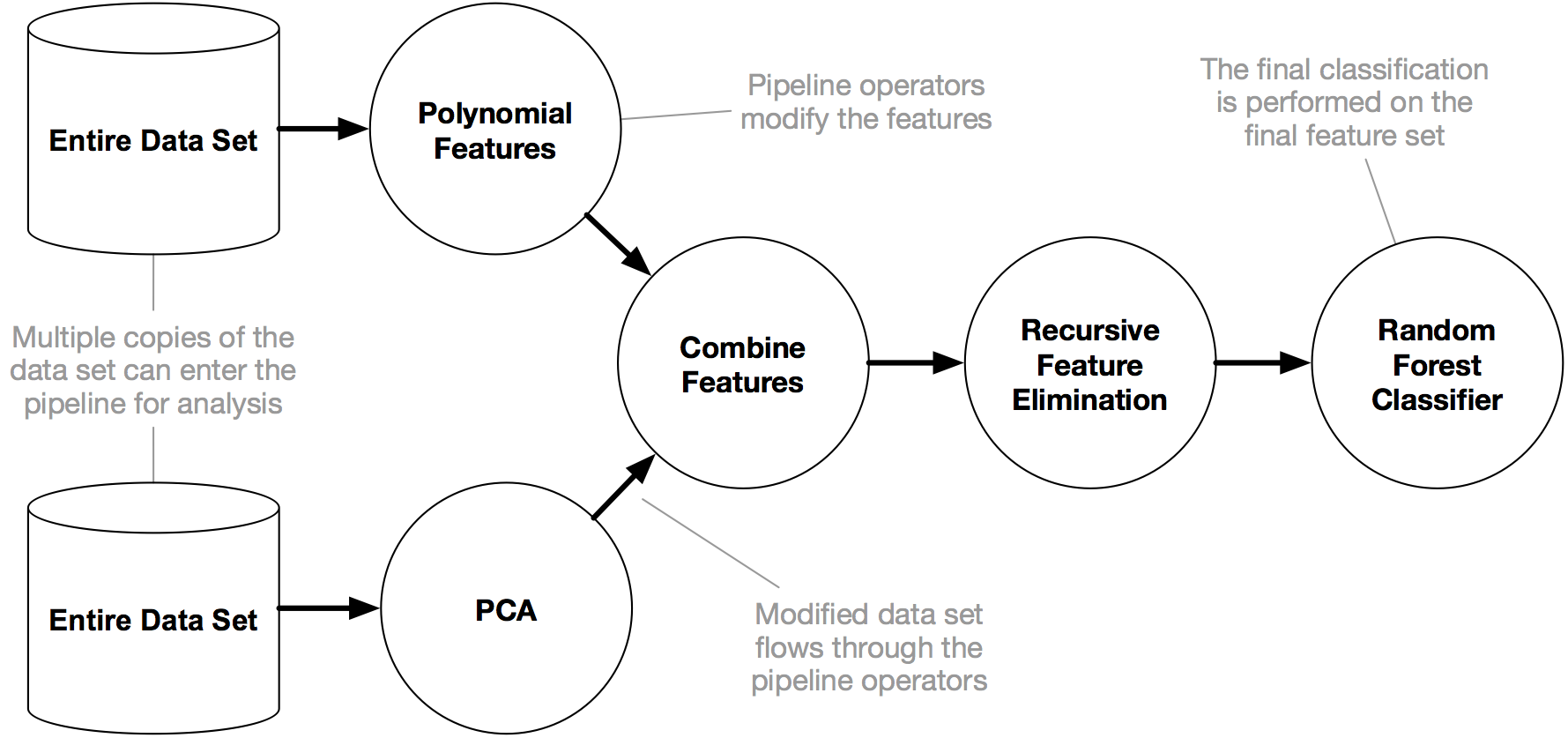
Example TPOT pipeline (from https://epistasislab.github.io/tpot/)
Documentation: Here is the documentation link.
Code example:
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64),
iris.target.astype(np.float64), train_size=0.75, test_size=0.25, random_state=42)
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
AutoKeras
AutoKeras is an open-source software library for automated machine learning developed by DATA Lab at Texas A&M University. Built on top of the deep learning framework Keras, AutoKeras provides functions to automatically search for architecture and hyper-parameters of deep learning models.
AutoKeras follows the classic scikit-learn API design and therefore is easy to use. The goal of this framework is to simplify ML practice and research by using automatic Neural Architecture Search (NAS) algorithms.
Documentation: Here is the detailed documentation link.
Code example: Here is a sample code example for the MNIST image classification task.
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import autokeras as ak
# Data loading
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Initialize the image classifier.
clf = ak.ImageClassifier(overwrite=True, max_trials=1)
# Feed the image classifier with training data.
clf.fit(x_train, y_train, epochs=10)
# Predict with the best model.
predicted_y = clf.predict(x_test)
print(predicted_y)
# Evaluate the best model with testing data.
print(clf.evaluate(x_test, y_test))
Summary of AutoML Systems & Their Importance
In this article, we started by explaining the core idea behind automated ML frameworks, or the so-called AutoML systems. We described their utility and why they are gaining traction in various business and technology organizations. We also showcased some prominent AutoML libraries and frameworks with relevant code examples and architecture illustrations as applicable.
Learning about these powerful frameworks will be beneficial for any upcoming data scientist as they will continue to grow in capabilities and widespread usage.
Let us know about any topics you're interested in by dropping a comment below, or feel free to contact us at any time with questions you have.
Bio: Kevin Vu manages Exxact Corp blog and works with many of its talented authors who write about different aspects of Deep Learning.
Original. Reposted with permission.
Related:
- How to Create an AutoML Pipeline Optimization Sandbox
- Fast AutoML with FLAML + Ray Tune
- Top 18 Low-Code and No-Code Machine Learning Platforms